As organizations begin to move full throttle into enhancing internal and external business outcomes, the term ‘digital transformation’ has gained supreme status into the particular tech lexicon. Digital transformation has become an important strategy for organizations for years and is predicted to be a crucial factor in the competition of who remains in the business.
The term digital transformation is defined as the particular integration of technology into all areas of the business, fundamentally changing how it operates and delivers value to its customers. Digital transformation is also a cultural change that requires organizations to continually challenge the status quo, experiment, and get comfortable with failure even if that happens.
Research analysts believe that when it comes to a timeframe, 85% of key decision makers feel they have only 2 years to get in order to grips with digital transformation. So, while the past few years have seen some movement in digital transformation, there’s now an urgency, as time becomes the new benchmark associated with which businesses stay in the race and which ones drop out.
Important Change For Every Business
Digital transformation has increasingly become very important for every business, from small businesses to large enterprises. This is quickly becoming widely accepted with the increasing number of panel discussions, articles, and published studies related to how businesses can remain relevant as the operations and jobs become increasingly digital.
Many business leaders are still not clear with what digital transformation brings to the table, while many believe that it is all about the business moving towards the cloud. Business leaders in the C-Suite are still in two minds of the changes they have to take into their strategies and forward way of thinking. Numerous believe that they should be hiring an external agency for change implementation, whilst many still question about the costs involved in the particular process.
As every organization is different, so are their digital change requirements. Digital transformation has the long legacy and extends much beyond 2023. It is a change which requires businesses to experiment often, get comfortable with failing, and continually problem the status quo. It also means that companies have to move beyond the age-old processes and look out for new challenges and changes.
Here is what the essence of digital transformation brings to the table:
• Customer experience
• Culture and leadership
• Digital technology integration
• Operational Agility
• Workforce enablement
Digital transformation can be predominantly used within a business context, bringing change into the organizational structure, impacting governments, public sector agencies and enterprises which are involved in tackling societal challenges such as tracking pollution, the sustenance levels and so on by leveraging one or more of these existing plus emerging technologies.
Digital Transformation 2023 and Beyond
Because digital transformation techniques mature, and its status as an innovation driver becomes a new standard, leading IT professionals are usually asking – what’s next? If the particular lesson from the last decade was the power of digital flexibility, how can it create a more efficient and productive workforce moving forward?
Today’s businesses are as diverse as the clients they serve. From the cloud-native startup to the legacy enterprise, as companies have embraced the value of electronic flexibility, an overwhelming majority have embarked on digital modification journeys.
One critical aspect of the approach to digital transformation is that IT departments are progressively expected to take the greater role in driving overall company goals.
As technology gets more advanced, the human element becomes significantly vital. The digital transformation saw a seismic shift in the way IT leaders strategy their infrastructure, but workplace transformation requires a deep understanding associated with the unique way’s individuals approach productivity.
In essence, many businesses have begun their journey, and have started making changes in their strategies within the business’s large digital programs adapting to AI initiatives and modern technologies. In most cases, it is simply a humble beginning and a whole lot more needs to be achieved.
Technologies are evolving and changing, challenging the particular fundamental strategic and operational processes that have defined organizations up until now.
In the times to come, enterprises will no longer have separate digital and AI strategies but instead will have to integrate corporate strategies deeply infused with changing technologies.








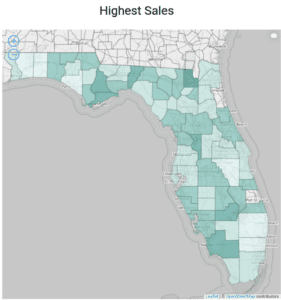
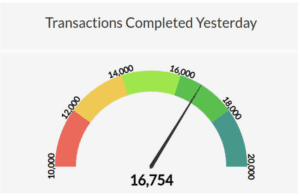 A gauge is an exceptionally clear visual. It shows exactly where a number falls between a minimum value and maximum value. If you want to show how your sales performance was for a specific time period, a gauge will allow a user to instantly know if you did better or worse than expected.
A gauge is an exceptionally clear visual. It shows exactly where a number falls between a minimum value and maximum value. If you want to show how your sales performance was for a specific time period, a gauge will allow a user to instantly know if you did better or worse than expected.