What is Marketing Analytics?
Analytics, at its core, is the study of numbers. Numbers provide valuable data and insight into any given marketing strategy by making performance quantifiable. With marketing analytics specifically, the numbers help to track, identify, and understand user behavior.
Understanding your audience is critical to making sound marketing decisions that deliver the best ROI and drive positive growth.
In a simplistic breakdown, marketing analytics are intended to perform in two ways:
1. Measure the effectiveness of marketing strategies and campaigns.
2. Identify opportunities for improvement that will yield greater results.
Why Do Marketing Analytics Matter?
Without marketing analytics, a business is operating blind. The marketing campaigns are merely pushed out to the world with little to no understanding of how strategies are landing with your audience.
Marketing analytics matter because:
- It makes the actions quantifiable. Whenever numbers are used, it provides concrete data for the marketing program. For example, it’s easy to notice that overall sales increased after a personalized content marketing campaign. Though, a more effective approach would be tracking the specific percentage (25% e.g.) of traffic that came from a blog published at a specific time (November, e.g.) and converted a specific number of leads (5% e.g.) for a specific product (holiday gift, e.g.).
- It helps plan for future marketing. When you understand which tactics are working, you can strategically plan for future marketing. Not only does this help with planning marketing activities, but also overall budget allocation.
- It identifies the “why” of what did or didn’t work. After a marketing campaign or strategy has launched, the only way to adequately understand performance is with marketing analytics. The data can be drilled down to track individual messaging across a broad spectrum of outlets, ensuring no approach is wasted. For example, maybe your click-through rates from social media to your website are fantastic, but not converting to sales. With this information, you can focus your energy on shifting the homepage to reduce bounce backs.
How Can Marketing Analytics Drive Growth?
Ultimately, the information provided by marketing analytics is meant to drive growth and provide positive ROI. There are a few key ways that marketing analytics can help drive growth:
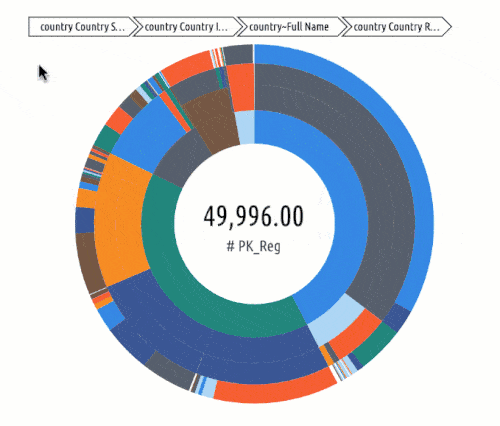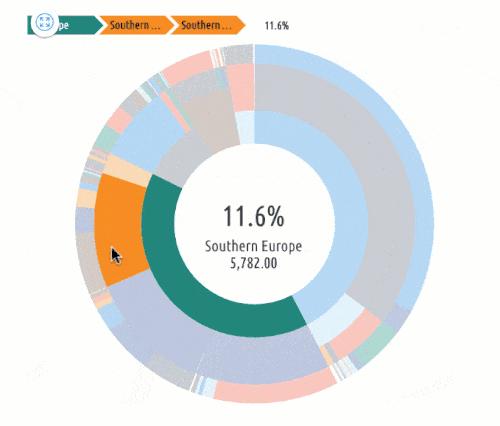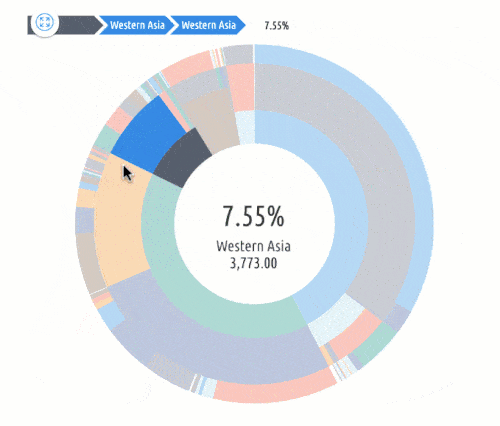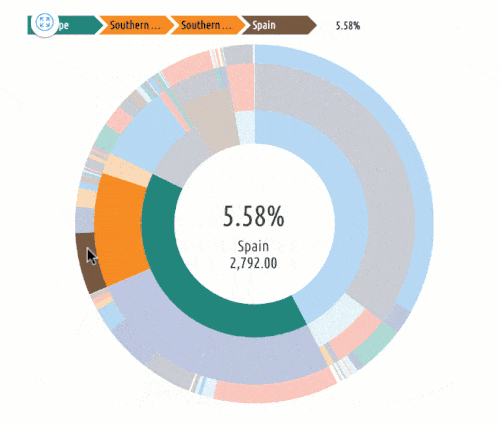
Identify target audiences. One of the most brilliant things that marketing analytics can do for businesses is to segment audiences. The analytics can help identify and group users by:
- Age
- Gender
- Geographic Location
- Income Level
Even further, marketing analytics can identify subgroups or intersections in data sets. For example, a segment could be women, aged 30-45, in Tulsa, OK.
When grouping users together, data can be extracted surrounding how to best target those groups. Marketing analytics can also reveal new groups that are worth targeting. For example, perhaps the target audience is believed to be women aged 30-45 years old, but you find that certain marketing tactics are delivering positive results in teenage boys aged 16-20 years old. Having that information is powerful when driving growth.
Predict future user trends. Predictive analytics compile past trends and historical data to help determine how users will behave in the future. This can help plan marketing strategies to align with certain seasonal behaviors. For example, sales of certain products are higher during the summer. By targeting audiences in the discovery phase in spring yields the most beneficial results.
Eliminate what doesn’t work. One of the best ways to reap rewards with marketing is to eliminate the tactics and strategies that aren’t working. The less time and money spent on fruitless endeavors, the more growth can happen.
Which Marketing Analytics Deliver the Best ROI?
The answer to this question will be different for each business. However, some general items will ensure marketing analytics deliver the best ROI.
1. High-Quality Data
The power is in the numbers. Data that is quality both in scope and extraction is so important to delivering the best marketing ROI. The best quality data will be:
- Current
- Consistent
- Precise
- Accurate
- Relevant
2. Combine Past, Present, and Future Data
To achieve a comprehensive overview of marketing analytics, all data should be considered. The past provides insight into user behavior and trends, while the present focuses on relevant current climates. The future is a prediction based on past and present trends, therefore eyes must also be turned toward the future to properly steer marketing strategies.